The DIP strategy and the SIC tactic
01/10/2025
From more than 40 years of software development, a way of working eventually emerges: the DIP strategy and the SIC tactic. Let’s dive deeper into these DIP and SIC processes.
DIP here stands for Data, Interface and Program
These are the main preoccupations for a seasoned developer, in that order.
Indeed, the first thing to consider is on what data we are working; data here expands to its structure. There is no way to write a single line of code without knowing on what data it will work.
The next thing to consider is which interface we need on this data to achieve the goal of the program we want to write. Note that “interface” here is to be taken in a wide meaning: the human to machine interface of course but it can be also a computer-to-computer interface and even a programming interface as we'll see.
Eventually, once these two preliminary steps decided, we can start to figure out which instructions we have to apply on the designed data to fulfill the expected interface.
It’s not a straightforward process though. Thinking about the interface may result in adapting the data structure. And writing the first lines of code often results in redesigning the data and interface.
An example
Here is an example of how it applies with a first mise en abyme as we will deal with exploiting the responses of an API.
Nowadays, API (Application Programming Interface) are common. They are provided to expand the possibilities of software. For an API, it’s a widely used convenience to get the results of any query in a JSON (JavaScript Object Notation), a format widely adopted as a standard of information exchange. That’s how it looks:
{"data":[{"id":"1936818009898921984","name":"Kluhoo","username":"Kluhoo5162351"},{"id":"1935064646828048384","name":"Prawcev","username":"Prawcev772326"},{"id":"1931791547059838976","name":"Qooxo","username":"Qooxo432"}],"meta":{"result_count":3,"next_token":"03G9CL7GGJ45KZZZ","previous_token":"0186A7A818FQAZZZ"}}
Which is, presented in a more readable format:
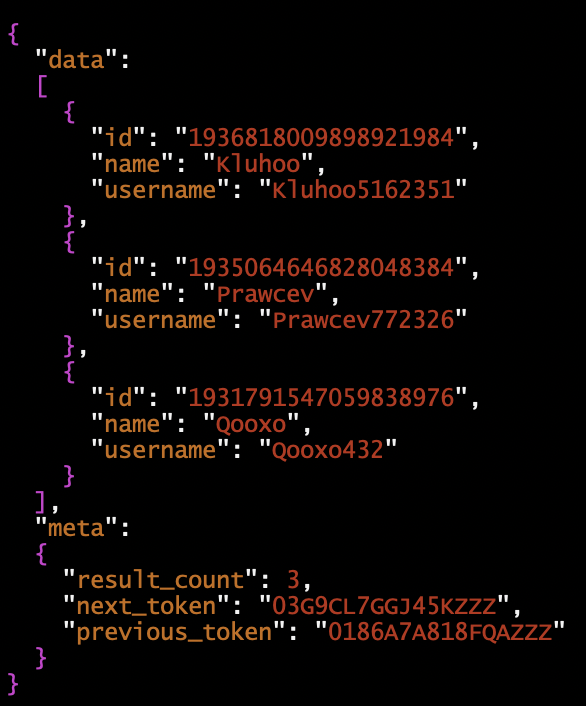
What we are considering is quite obvious: it’s an object with two members, “data” and “meta”. Furthermore, “data” value is an array of three objects, each having three properties: an “id”, a “name” and a “username”. And “meta” is another object with three properties: a “result_count”; a “next_token” and a “previous_token”. Our job here is to process the three objects in the array and to record the next_token value for future use.
Data
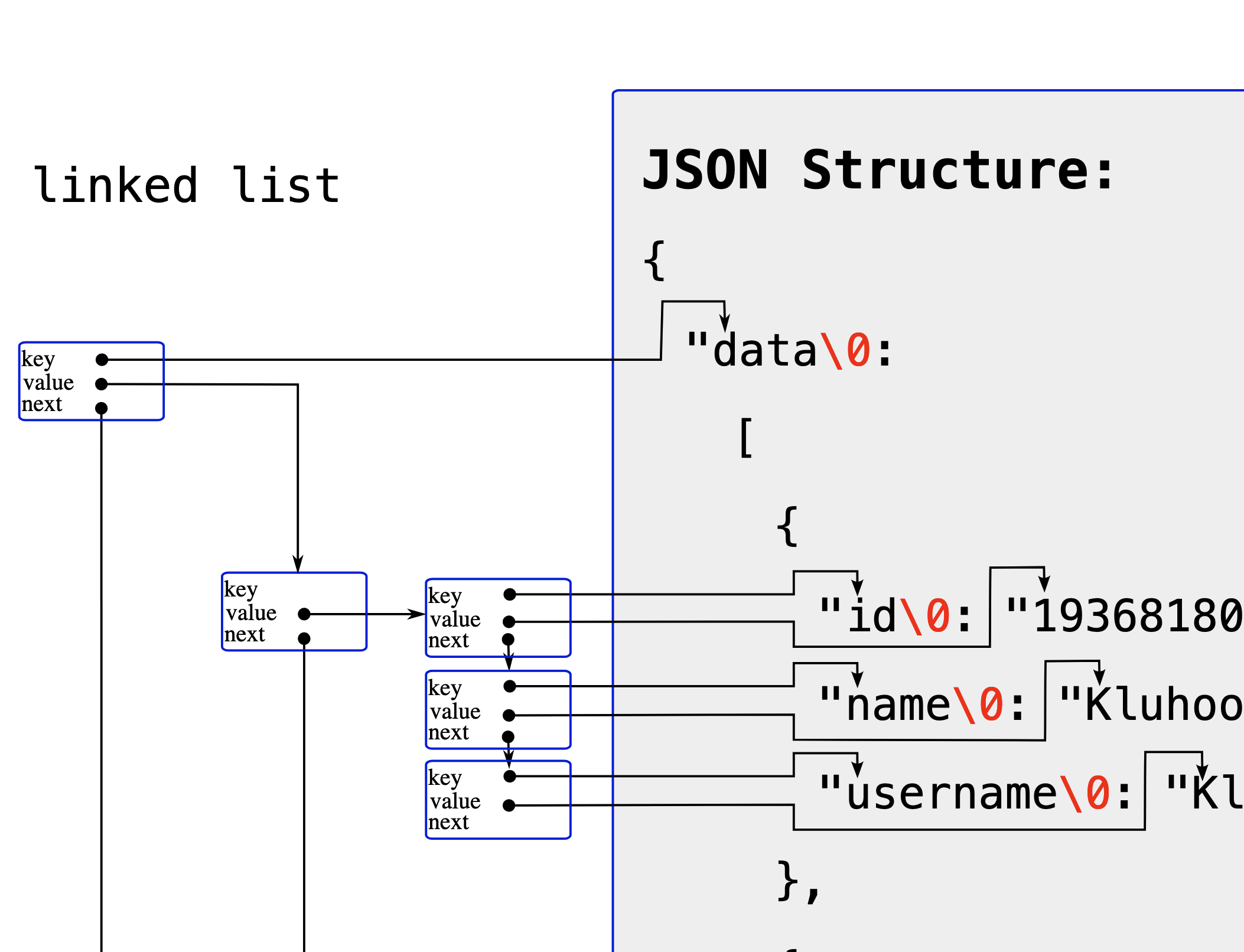
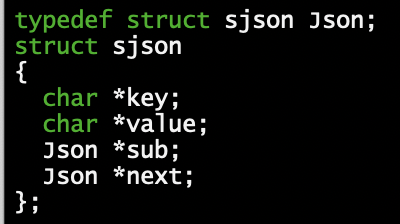
The data structures of our program must hold a recursive list of (key, value).
In C (of course, as it is the most powerful language), a character string (a text) is a sequence of characters (char) with a pointer (char*) to its beginning and a special ‘\0’ (zero) character value added at its end. We already have the full API response text as such a string. The only thing remaining to do is to put the required pointers at the beginning of each relevant strings and to squash the following character with the ‘\0’ marking the end of the string.
What we want to achieve is illustrated by the figure below:

To do so, we will use one of the most versatile data structures for it: a linked list:
Starting inside out, we first set the pointers to the (key, value) of each member of the deepest objects in the structure. The linked list concept is here to gather all (key, value) of each object, and also to gather all objects in the array and, above the two complex members values of the topmost object (the one which members are “data” and “meta”).
Indeed, the possible value of each node is either a text or a node, recursively.
Interface
What we need to do with this data is rather simple:
- parse the API response text to split it in Json data structure,
- print a Json (for debugging purposes),
- find the value of a given object member from its key,
- free the dynamically allocated Json structure.
For these four actions on the data, we choose five simple functions:
- Json *Jparse(char *);
- void Jprint(Json *,int);
- char *Jvalue(Json *,char *); or Json *Jsub(Json *,char *);
- void Jdel(Json *);
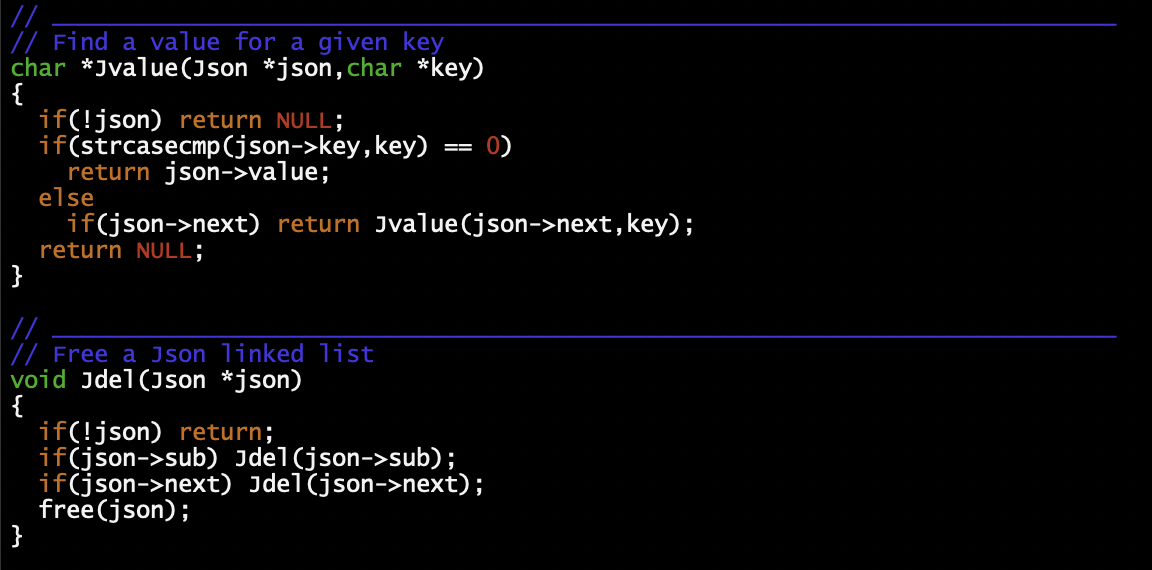
The Jparse() creates the recursive linked list of Json from the API response text and returns a pointer to the first Json.
The Jvalue or Jsub returns either the text value of a given key or a pointer to the first Json if the value is itself an object or an array of values.
Program
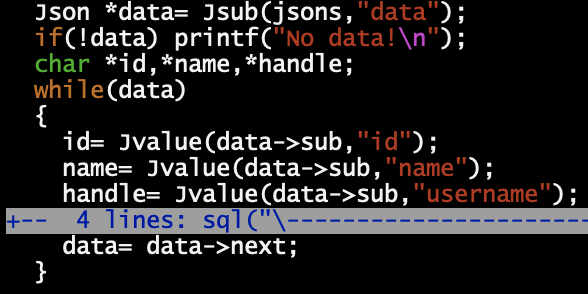
With a notable exception for the Jparse(), the code of these functions is straightforward. For examples:
But using these functions is even simpler and that's the most important. To work with the API's response text (rep being a char* pointing to it), all we have to do is:
SIC
That is where the SIC tactic comes into the picture.
SIC here stands for Simple, Intelligible and Concise.
This time it is not sequential but parallel, all at the same time, each quality strengthening each-others. If it's simple it’s more likely intelligible, if it's intelligible it’s more likely concise. If it's concise, it’s more likely simple. Note that simplicity does not apply to the concept that is handled by the program but the way it is handled. The example above illustrates it. Working on a recursive data structure is not simple but needs to be handled as simply as possible. The idea is to add no complexity. Being the only one able to understand what you write does not mean that you are cleverer than others but just that you failed to express yourself.
Here how SIC applies for our example.
For the purity of the concept, we could merge char *value; and Json *sub; in a void *value;, having a single void *Jvalue(). But that would require some casts such as (char *) or (Json *) for each use of Jvalue(). Moreover, within the Jdel(), we would need to know if the value pointed at is another Json that we must free or a string that we must not free. That would have needed at least a Boolean value to record it.
But the SIC tactic is even better illustrated by a comparison with another JSON librairy. Using json-c library requires:
- a json_tokener and json_object pointers,
- initializing the json_tokener with a call json_tokener_new()
- parse the json string with a call to json_tokener_parse_ex, specifying the length of the string to parse
- retrieve each json_object with a call to json_object_get_ex()
- retrieve each char* string with calls to json_object_get_string()
- free both the root object and the tokener
Lengthy type and function names are a pain to type and read and the resulting code is heavy!
That is what motivated the conception of an ad hoc program used to illustrate the DIP strategy and SIC tactic.
Another initiative, jsmn, appears to be even simpler but fails to handle recursive JSON structures.
Conclusion
There is no radically new ideas presented here as it aligns with concepts like data-first design and simplicity in coding which are established practices (e.g., data modelling, interface design, and clean code principles)
These approaches are presented as something that might inspire them.